
You maybe might be in the same position, you want to gather some data of different objects (like financial data from different entities) from a website, and you copy/paste thousands times from website to your local worksheet. The work of collection makes you exhausting. Believe me, I have been there as you did.
To collect and format data more efficiently and nicely, we will create a little program to solve the problem for us. Afterwards, it will only take a few seconds to retrieve the online data.
The article is split into two parts:
- The first part introduces how to locate the data points we want in the HTML of the website.
- The second part shows you how to apply that knowledge in an automated way with a small NodeJS script.
This part is going to start with an example of collecting financial information of Apple Inc. from a stock market website, martketwatch.com.
The URL path is: https://www.marketwatch.com/investing/stock/aapl/financials
.
The approach I will show is based on the assumption that there is no API available which could be used directly. In the case of martketwatch.com, they render the data on the server, which means the rendered page needs to be parsed. So let us do that!
Now, to help us research how to get to the precious data, let us make use of jQuery. It has the same interface as cheerio, which will be used later.
To use jQuery on the current website, execute the following in the developer console. It adds a script tag to the website which will load the jQuery library for our use.
var script = document.createElement('script');script.src = "https://code.jquery.com/jquery-latest.min.js";document.getElementsByTagName('head')[0].appendChild(script);
Then the $ should be available. In case it is not available, maybe due to CSR policy of the website, the last option is to copy the content of <em>https://code.jquery.com/jquery-latest.min.js</em> and paste and execute it in the developer console.
Give it a test and select all input tags on the website:
$(‘input’)

You should now see that there are some input tags found by the jQuery selector. This is great, the groundwork is laid for our adventure!
Now, let us see how we can select the data we want, in this case, the financial data of the stocks of brand with a bitten fruit.
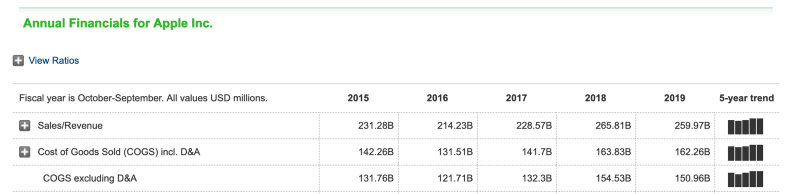
The data we are interested here are the sales from the year 2015 to 2019, the question is, how can we extract them? Well, you might have guessed it, with the jQuery selector. Let us have a look at the HTML of it. With the element selector of your developers tools, you can select the element in the view.

After selecting a field, the element will be located in the HTML.
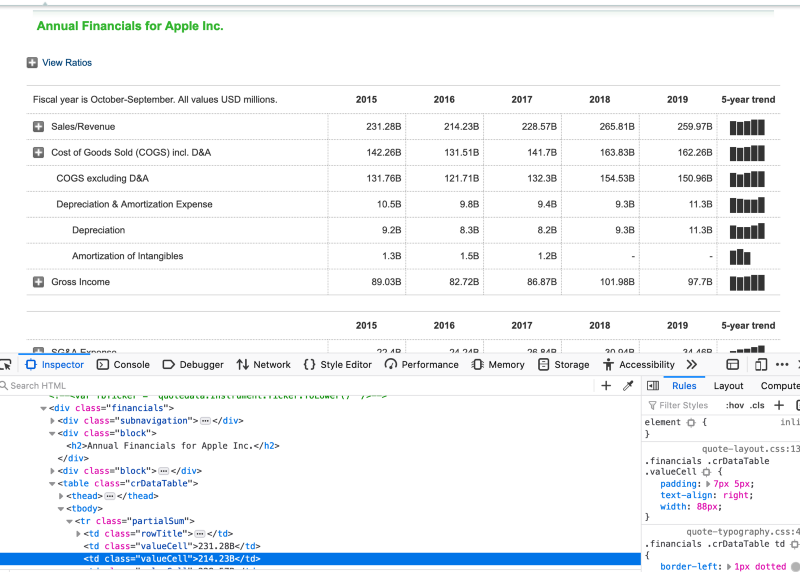
Looking at the surrounding HTML, there is a div tag with the class financials. Inside of that tag is the actual table tag, which has a tbody tag. That one contains a tr tag which contains the td tags with our precious data we want to collect! I hope you could follow me here so far :)
Let us try to come up with a selector that will work for jQuery. Clearly the financials class looks like a perfect anchor, due to being unique in the HTML. Next let us try to select only the class valueCell.
$('.financials td.valueCell')
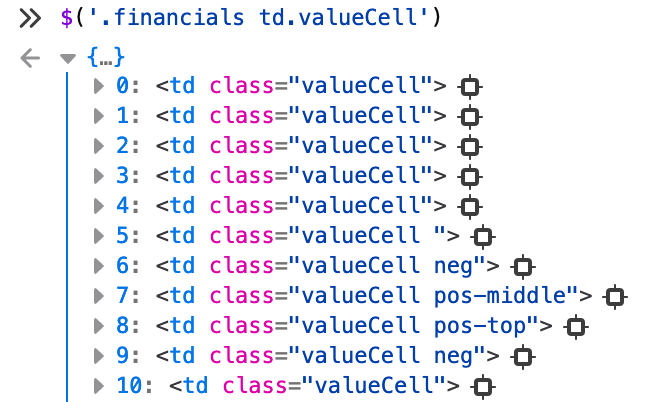
Now this is a bit to broad and we have too many valueCell class tags selected, we need to narrow it down a bit. After looking at what kind of other tags were selected, it seems that we need to constrain it down to the first row of valueCell class tags. Luckily, there is a tr tag which has the class partialSum.
$('.financials tr.partialSum:nth-child(1) td.valueCell')
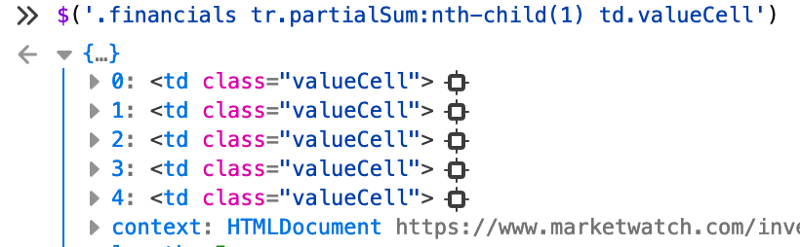
This leaves us with exact the cells we want to look up! Next step is too use it in our automation!
References:
<strong>jQuery Selectors</strong><br> _Well organized and easy to understand Web building tutorials with lots of examples of how to use HTML, CSS, JavaScript…_www.w3schools.com
<strong>Selectors | jQuery API Documentation</strong><br> _To use any of the meta-characters ( such as !"#$%&’()*+,./:; [email protected][\]^`{|}~ ) as a literal part of a name…_api.jquery.com
Originally published at <em>https://dev.to</em> on May 4, 2020.